Week 3: Web Scraping
| web-scraper-order | web-scraper-start-url | news headline |
|---|---|---|
| 1697795180-1 | https://www.bbc.co.uk/news | Rising homelessness could bankrupt seaside town |
| 1697795180-2 | https://www.bbc.co.uk/news | Coaches can't keep up with my questions - Raducanu |
| 1697795180-3 | https://www.bbc.co.uk/news | Care crisis: People forced to pay or wait |
| 1697795180-4 | https://www.bbc.co.uk/news | Warm weather in September hits autumn coat sales |
| 1697795180-5 | https://www.bbc.co.uk/news | Don't dress as Barbie at Halloween, striking Hollywood actors told |
| 1697795180-6 | https://www.bbc.co.uk/news | Elon Musk says X to have two new premium tiers |
| 1697795180-7 | https://www.bbc.co.uk/news | Megan Thee Stallion settles legal battle with label |
Between week 2 and 3, we covered aspects of HTML (hence this website's existence) and web scraping. In the workshop of week 3, I opted to use webscraper.io to build a web scraper, which you can see above. Initially we discussed OutWit Hub as a scraper to try although this was problematic with my laptop's operating system, so webscraper.io - a Chrome extension - was decided as a better fit. I also tried ScrapeHero, which felt very user friendly, and an approachable way to scrape data (although there was a limited option of websites to scrape with a free account).
I found the process itself fairly straightforward to execute - thanks to the advice given via Minerva and within the workshop - and to try and make sense of the digital research method, I opted to scrape some headlines from BBC News. In a research setting, some sort of pattern might emerge from a larger dataset, allowing for critical analysis and interpretation.
I then gave things a try on Google Colab, to scrape the 'Programming Buddies' group on old reddit. Following the instructions made this understandable; see below for the code and printed outcome.
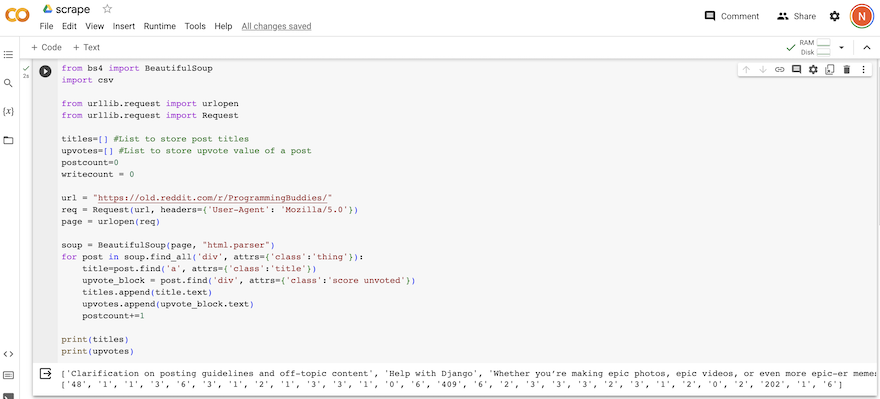
I then played around with outputs and managed to get the data written out in the format of subreddit title / upvote number, as seen below...
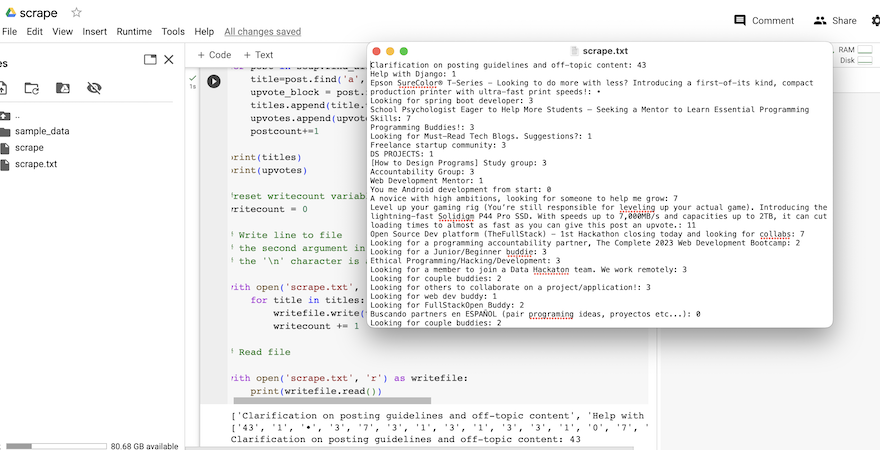
I plan to trial this with other websites, and/or subreddits, to develop my skills.
It should be considered that, from a research perspective, solely relying on web scraping might overlook particular types of data. It could be missed by the scraper, or a website's source HTML change therefore impacting the scrape. With that in mind, though, web scraping can also be useful in occasions such as audience/consumer study (eg by scraping from social media comments), or, in academia, research to find patterns which might suggest or uncover certain phenomena.
Personally, I would be interested to try and scrape data from a website such as Instagram, or X, specifically its comment section of, for example, a footballer. There is often talk of a rise in online abuse towards sportspeople and scraping data comments might enable statistics to be produced to back up a campaign to stop online abuse.